RCU同步机制在2002年10月份添加到Linux内核 [3]。RCU的读者拥有最高的优先级,读者不会阻塞。写者拥有最低的优先级。某一时刻,RCU的多个读者可能访问的是两份不一致的数据。
RCU就像火车轨道的变轨,变轨是一个原子操作,火车要么驶入左侧轨道,要么驶入右侧轨道。对于写,如果轨道从左侧变轨为右侧,如果要释放左侧轨道,只有当左侧轨道的所有火车都使出左侧轨道后,才可以安全的去掉。RCU也是类似的,读者访问数据,无需任何等待,它只要拿到数据指针,然后访问,但读者在访问数据期间,可能版本(指针)已经更新了,此时读者继续访问旧数据,直到访问结束。而写者要更新一个新版本,它首先创建新的版本,然后保存旧版本的指针,然后让指针指向新版本,这个切换(指针赋值)是一个原子操作,当到达一个关键点的时候,所有对旧版本的访问已经结束,就可以安全的释放旧版本。RCU通常用在对数据容许一定不一致但对读性能要求非常高的场景,比如路由表。
RCU利用了内核一种机制,比如当所有的CPU核都发生了一次上下文切换之后,那么所有对旧版本的数据的访问都已结束,此时可以安全的释放旧版本的数据。
Publish-Subscribe Mechanism
RCU的发布订阅机制 [3],类似轨道的变轨,在计算机中,指针的读取和赋值是一个原子操作。但是简单的赋值会存在问题,比如下面的代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 | struct foo { int a; int b; int c;};struct foo *gp = NULL;/* . . . */ p = kmalloc(sizeof(*p), GFP_KERNEL);p->a = 1;p->b = 2;p->c = 3;gp = p; |
由于编译器和CPU均可能乱序,所以gp = p 可能在p的成员赋值前发生。这样读者可能就读到一个未初始化的p成员。因此RCU提供了发布的接口:rcu_assign_pointer(gp, p); 这个接口会添加compiler和CPU barrier,防止乱序。
类似的,下面的代码也是不安全的,虽然看起来不会乱序,但是DEC Alpha架构的CPU和编译器值预测优化可能将p->a的提取发生在p赋值之前 [3]。
1 2 3 4 | p = gp;if (p != NULL) { do_something_with(p->a, p->b, p->c);} |
RCU提供了订阅的接口:p = rcu_dereference(gp); 这个接口和发布接口类似,添加了compiler和memory barrier,防止乱序。
RCU除了直接用在指针外,更多的是用在双向链表和哈希链表,RCU发布订阅的接口:
| Category | Publish | Retract | Subscribe |
| Pointers | rcu_assign_pointer() | rcu_assign_pointer(..., NULL) | rcu_dereference() |
| Lists | list_add_rcu() list_add_tail_rcu() list_replace_rcu() | list_del_rcu() | list_for_each_entry_rcu() |
| Hlists | hlist_add_after_rcu() hlist_add_before_rcu() hlist_add_head_rcu() hlist_replace_rcu() | hlist_del_rcu() | hlist_for_each_entry_rcu() |
RCU is a Way of Waiting for Things to Finish
RCU的极其强大之处在于,它可以等待几千个不同的事情完成,而不需要显式的追踪它们 [4]。还不用担心性能退化、灵活性限制、复杂的死锁场景,以及追踪导致的内存泄漏风险。
和自旋锁等不同,RCU不用定义一个类似spinlock_t的变量来显式的追踪每一个RCU保护区。RCU是全局的,这是由RCU的设计决定的,这也是RCU不同于其它同步机制的一个显著特点。
RCU的读者虽然拥有无限的优先级,但是读者仍然有一个关键区:RCU read-side critical sections。关键区以rcu_read_lock()开始,以rcu_read_unlock()结束。RCU需要rcu_read_lock(),因为RCU需要防止关键区被抢占等(依赖于RCU的类型),rcu_read_lock()的作用是关闭抢占、软中断等。RCU的关键区可以嵌套,可以包含非常多的代码,只要代码不显式的阻塞或者睡眠。但是也有一种特殊的RCU叫做SRCU,允许在SRCU的关键区睡眠。
Grace Period
Grade Period是这样一个区域,某一点到这一点之前的所有关键区结束的区域,Grace Period结束,意味着所有对Grace Period之前被替换的旧数据的访问都结束了。所有Grace Period开始之前的RCU关键区已经结束,那么Grace Period就已经结束。但是要到一个检查点(quiescent point),才做这个检查。
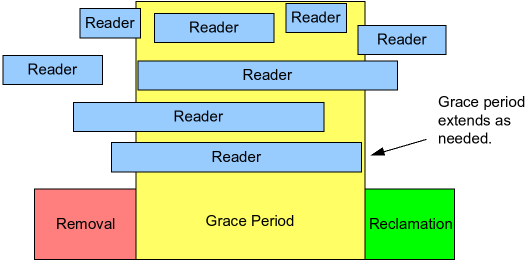
如上图,Grace Period开始之后的RCU关键区,仍然可以扩展到该Grace Period之后。
下面的流程,讲述了RCU等待读者的算法:
1 做出改变,比如替换双向链接的元素
2 等待已经存在的RCU read-side critical sections全部完成(如使用synchronize_rcu())。后续的关键区不可能引用被删除的元素,所以过了这一步第3步就安全了。
3 做清理,比如释放被替换的元素。
下面,进入RCU的深水区了。RCU的原理我们大致有了一些了解。那如何等待Grade Period结束呢。
synchronize_rcu()第一眼看起来让人有点迷惑,毕竟它要等待所有的RCU read-side关键区结束,按我们之前说的,用rcu_read_lock和rcu_read_unlock分割的关键区,在没有开启CONFIG_PREEMPT的内核中,甚至不产生任何代码。
有一个诡计,RCU Classic read-side critical sections不允许block或者sleep。因此当给定CPU执行了context switch,那么我们可以保证,任何运行在该CPU上的所有RCU read-side critical sections已经完成。这也意味着,只要所有CPU都执行了上下文切换,意味着Grace Period结束。
因此synchronize_rcu()可以简单的实现为:
for_each_online_cpu(cpu)
run_on(cpu)
上面的实现太过粗暴。实际上,RCU直接是内核的一部分,它在内核的调度器里面都有检查点。RCU是直接实现在内核的最核心代码里面的。
Maintain Multiple Versions of Recently Updated Objects
例子1: 删除
代码:
1 p = search(head, key);
2 if (p != NULL) {
3 list_del_rcu(&p->list);
4 synchronize_rcu();
5 kfree(p);
6 }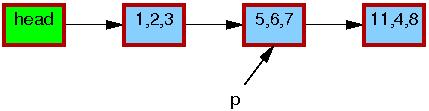
第一步,查找到p
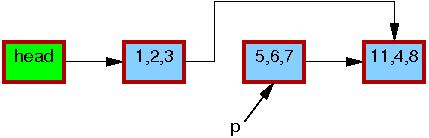
第二步,list_del_rcu()删除p
例子2:替换
代码:
1 q = kmalloc(sizeof(*p), GFP_KERNEL); 2 *q = *p; 3 q->b = 2; 4 q->c = 3; 5 list_replace_rcu(&p->list, &q->list); 6 synchronize_rcu(); 7 kfree(p);
第一步,拿到p。
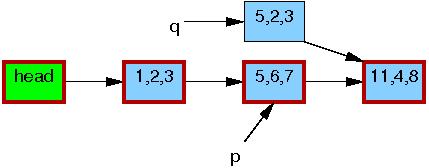
第二步,拷贝p到q,并更新q的字段。
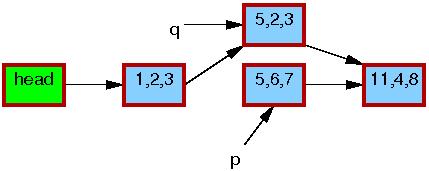
第三步,执行完list_replace_rcu()
在linux运行的所有系统中,load和store指针的操作都是原子操作,如果load和store同时发生,load读取的要么是之前的指针,要么是store之后的指针,不会是两者的位混合。
RCU Overview
隐藏在RCU后面的基本思路是,把update分割为removal和reclamation两个phase。
removal phase移除对一个对象的引用,在modern CPU里面,移除是安全,要么看到的是新版本,要么看到的是旧版本,移除是立即完成的。
而reclamation phase则延后到所有对旧对象的访问已经结束才开始。这样才能安全的回收旧对象。内核有这个能力能确定这个延后时间点。
WHAT IS RCU'S CORE API
核心的API就下面5类,其它的API都可以用这5类实现出来。
rcu_read_lock()
reader使用这个接口来进入RCU read-side critical section,在关键区里面不可调用阻塞的接口。如果内核开启了CONFIG_PREEMPT_RCU,那么可以抢占RCU的关键区。
rcu_read_unlock()
reader使用这个接口来结束RCU read-side critical section。RCU read-side critical secitons可以嵌套或重叠。(nested and/or overlapping)
synchronize_rcu()
updater使用这个接口来等待Grace Period结束。重申:synchronize_rcu()只等待调用synchronize_rcu()那一刻之前的正在进行的关键区结束。调用那一刻之后的关键区没必要等待。当然synchronize_rcu()也不会在所有关键区结束的时候立即返回(没有这个能力,或者实现这个能力代价过大,也没必要),而是在内核的某个检查点之后才返回,因此存在一定的scheduling delay。
call_rcu()
是synchronize_rcu()的回调版本。它不阻塞,而是注册一个回调函数。然而不能轻易的使用call_rcu(),使用synchronize_rcu()可以产生更简单的代码,而且有一个非常好的属性,就是可以限制更新的速率,直到grace period delay。这样可以避免denial of service攻击,使用call_rcu()要注意限制更新的速率。
rcu_assign_pointer()
updater使用这个接口来更新指针,从而更新一个版本。
rcu_dereference()
reader使用这个接口来读取指针,从而获得一个版本。
RCU性能
参考文档4,讲述了RCU的一些性能比对结果,相比读写锁,RCU有着明显的优势。

RCU的另外一个显著的特点是,RCU不会发生死锁 (Deadlock Immunity)[4]。因为RCU本质上,读者有最高的优先级,读者无需等待某一条件完成,RCU的rcu_read_lock()只是做一些防止grace period结束的事情,比如在开启抢占的内核中禁止抢占。
RCU的另外一个显著特点是,RCU可以嵌套。
RCU's Requirements
1 Disabling preemption does not block grace periods
禁止抢占不会阻止grace period结束。曾经(Tiny RUC, Tree RCU)确实可以通过禁止抢占来阻止gp结束,但是这是那个时候的实现的一个意外,这不是一个requirement。某一个flavor的RCU(RCU-sched),禁止抢占不会阻止gp结束。Oleg Nesterov用实验证实了这一点。
2 Parallelism facts of life
任何cpu或者task都可能被delay。比如虚拟机被宿主机delay,NMI或ECC错误等。
compiler和cpu均可能reorder memory access。RCU也是一种锁,在关键区边界,也要阻止reorder。
Linux系统可能有几千个CPU,RCU要支持这种场景。
3 Interrupts and NMIs
RCU read-side critical sections和call_rcu(),均可以在interrupt handlers,以及中断禁止的地方调用。
RCU read-side critical sections可以在NMI中调用。但是call_rcu不行。
4 Loadable modules
当模块卸载后,调用模块的函数,访问模块的变量,都将导致段错误。因此模块卸载函数必须取消任何延迟的模块函数调用,比如del_timer_sync(),但是一旦调用了call_rcu(),RCU的回调没法取消。因此RCU提供了rcu_barrier(),它等待所有in-flight RCU callbacks被调用。
RCU Flavors
现在至少有5种flavors。我们经常谈论的是classic rcu,也就是primary flavor。
1 primary flavor
主要有两种实现:non-preemptible和preemptible。non-preemptible RCU,即classic RCU,它包括在Tiny RCU和Tree RCU。preemptible RCU,即Preempt RCU,也叫做RCU-preempt。
在内核配置中,当未开启抢占(!CONFIG_PREEMPTION)时,如果是SMP系统,则选择Tree CPU。如果是UP系统,则选择Tiny CPU,Tiny CPU的内存占用非常小。开启内核抢占,则选中CONFIG_PREEMPT_RCU,即使用RCU-preempt。
classic RCU的rcu_read_lock()会调用preempt_disable(),但实际上,在关闭抢占的内核才会选择classic RCU,因此,preempt_disable()只是扩展为一个barrier(),它的quiescent state有:context switch,idle,user mode,offline。
Preempt RCU的rcu_read_lock不会调用preempt_disable(),它只是current->rcu_read_lock_nesting++。因此抢占时打开的,它的关键区可以被抢占。
这些不带后缀的RCU API都属于primary RCU的API,如rcu_read_lock()。
2 bottom-half flavor
softirq-disable flavor of RCU,也就是RCU-bh。网络数据在软中断中处理,当网络负载很高时,某些CPU可能不会退出软中断执行,因此阻止了这些CPU发生上下文切换。应该gp也不会结束,
解决方法是,创建RCU-bh。它在进入read-side critical sections时执行local_bh_disable()。同时在从一种类型的软中断转移到另外一种类型的软中断执行作为一个quiescent state。
RCU-bh API包括
rcu_read_lock_bh(), rcu_read_unlock_bh(), rcu_dereference_bh(), rcu_dereference_bh_check(), synchronize_rcu_bh(), synchronize_rcu_bh_expedited(), call_rcu_bh(), rcu_barrier_bh(), and rcu_read_lock_bh_held().
3 Sched flavor
classic RCU等待GP有一个副作用,也等待了所有pre-existing interrupt 和 NMI handlers的结束。但是,引入preemptible-RCU之后,就没有这个副作用了,因为RCU read-side critical section之外的任何点可以是一个quiescent state (QS)。因此创建了RCU-sched。
他的rcu_read_lock(),会显示的调用preempt_disable()。因此在CONFIG_PREEMPT=n的内核中,RCU和RCU-sched有完全一样的实现。但是在CONFIG_PREEMPT=y的内核中。RCU是RCU-preempt。和RCU-sched不同。
RCU-sched API包括
rcu_read_lock_sched(), rcu_read_unlock_sched(), rcu_read_lock_sched_notrace(),
rcu_read_unlock_sched_notrace(), rcu_dereference_sched(), rcu_dereference_sched_check(),
synchronize_sched(), synchronize_rcu_sched_expedited(), call_rcu_sched(), rcu_barrier_sched(),
and rcu_read_lock_sched_held().
然而,任何禁止抢占的接口都被标记为RCU-sched的read-side critical section。包括
preempt_disable() and preempt_enable(), local_irq_save() and local_irq_restore(), and so on.
4 Sleepable RCU
过去10年,总有人说,我需要在RCU read-side critical中block。说出这句话的人,通常是不懂RCU的人。毕竟你如果需要block,那完全可以使用更高负载的同步机制。但是,随着linux kernel notifier的出现,这种情况改变了。它的read-side critical sections几乎不sleep,但是有时也需要。此时,引入了Sleepable RCU,即SRCU。
SRCU的一个显著不同,它不是全局的,它需要定义对应的domain。即一个srcu_struct实例。
int idx;
idx = srcu_read_lock(&ss);
do_something()
srcu_read_unlock(&ss, idx);
synchronize_srcu(&ss);
SRCU API包括
srcu_read_lock(), srcu_read_unlock(), srcu_dereference(), srcu_dereference_check(),
synchronize_srcu(), synchronize_srcu_expedited(), call_srcu(), srcu_barrier(), and srcu_read_lock_held().
也包括定义和初始化srcu_struct的接口:
DEFINE_SRCU(), DEFINE_STATIC_SRCU(), and init_srcu_struct()
5 Tasks RCU
用在使用trampolines的tracing等场景。
接口相当简单:
call_rcu_tasks(), synchronize_rcu_tasks(), and rcu_barrier_tasks()
RCU API
RCU has a family of wait-to-finish APIs
大API表如下:

第一行purpose很重要,给出了synchronize_rcu等待的对象,潜台词是QS有哪些。
如果觉得使用synchroniz_rcu()的grace periods太长了。可以使用synchronize_rcu_expedited()加快。但是CPU负载会显著增加。
混合使用RCU和RCU Sched有何问题?
答:对于关闭抢占的内核,这两者是相同的实现。为CONFIG_TREE_RCU或者CONFIG_TINY_RCU。混合没有问题。对于开启抢占的内核,RCU变成了RCU preempt(老的版本是:CONFIG_TREE_PREEMPT_RUC或CONFIG_TINY_PREEMPT_RCU)。此时RCU的关键区可以被抢占,但是RCU sched不能,混合使用是致命的(fatal)。
RCU has list-based publish-subscribe and version maintenance APIs
如下表
| Category | Primitives | Purpose |
|---|---|---|
| List traversal | list_for_each_entry_rcu() | Iterate over an RCU-protected list from the beginning. |
list_for_each_entry_continue_rcu() | Iterate over an RCU-protected list from the specified element. | |
list_entry_rcu() | Given a pointer to a raw list_head in an RCU-protected list, return a pointer to the enclosing element. | |
list_first_entry_rcu() | Return the first element of an RCU-protected list. | |
| List update | list_add_rcu() | Add an element to the head of an RCU-protected list. |
list_add_tail_rcu() | Add an element to the tail of an RCU-protected list. | |
list_del_rcu() | Delete the specified element from an RCU-protected list, poisoning the ->pprev pointer but not the ->next pointer. | |
list_replace_rcu() | Replace the specified element in an RCU-protected list with the specified element. | |
list_splice_init_rcu() | Move all elements from an RCU-protected list to another RCU-protected list. | |
| Hlist traversal | hlist_for_each_entry_rcu() | Iterate over an RCU-protected hlist from the beginning. |
hlist_for_each_entry_rcu_bh() | Iterate over an RCU-bh-protected hlist from the beginning. | |
hlist_for_each_entry_continue_rcu() | Iterate over an RCU-protected hlist from the specified element. | |
hlist_for_each_entry_continue_rcu_bh() | Iterate over an RCU-bh-protected hlist from the specified element. | |
| Hlist update | hlist_add_after_rcu() | Add an element after the specified element in an RCU-protected hlist. |
hlist_add_before_rcu() | Add an element before the specified element in an RCU-protected hlist. | |
hlist_add_head_rcu() | Add an element at the head of an RCU-protected hlist. | |
hlist_del_rcu() | Delete the specified element from an RCU-protected hlist, poisoning the ->pprev pointer but not the ->next pointer. | |
hlist_del_init_rcu() | Delete the specified element from an RCU-protected hlist, initializing the element's reverse pointer after deletion. | |
hlist_replace_rcu() | Replace the specified element in an RCU-protected hlist with the specified element. | |
| Hlist nulls traversal | hlist_nulls_for_each_entry_rcu() | Iterate over an RCU-protected hlist-nulls list from the beginning. |
| Hlist nulls update | hlist_nulls_del_init_rcu() | Delete the specified element from an RCU-protected hlist-nulls list, initializing the element after deletion. |
hlist_nulls_del_rcu() | Delete the specified element from an RCU-protected hlist-nulls list, poisoning the ->pprev pointer but not the ->next pointer. | |
hlist_nulls_add_head_rcu() | Add an element to the head of an RCU-protected hlist-nulls list. |
RCU has pointer-based publish-subscribe and version maintenance APIs
如下表:
| Category | Primitives | Purpose |
|---|---|---|
| Pointer update | rcu_assign_pointer() | Assign to an RCU-protected pointer. |
| Pointer access | rcu_dereference() | Fetch an RCU-protected pointer, giving an lockdep-RCU error message if not in an RCU read-side critical section. |
rcu_dereference_bh() | Fetch an RCU-protected pointer, giving an lockdep-RCU error message if not in an RCU-bh read-side critical section. | |
rcu_dereference_sched() | Fetch an RCU-protected pointer, giving an lockdep-RCU error message if not in an RCU-sched read-side critical section. | |
srcu_dereference() | Fetch an RCU-protected pointer, giving an lockdep-RCU error message if not in the specified SRCU read-side critical section. | |
rcu_dereference_protected() | Fetch an RCU-protected pointer with no protection against concurrent updates, giving an lockdep-RCU error message if the specified lockdep condition does not hold. This primitive is normally used when the update-side lock is held. | |
rcu_dereference_check() | Fetch an RCU-protected pointer, giving an lockdep-RCU error message if (1) the specified lockdep condition does not hold and (2) not under the protection of rcu_read_lock(). | |
rcu_dereference_bh_check() | Fetch an RCU-bh-protected pointer, giving an lockdep-RCU error message if (1) the specified lockdep condition does not hold and (2) not under the protection of rcu_read_lock_bh() (2.6.37 or later). | |
rcu_dereference_sched_check() | Fetch an RCU-sched-protected pointer, giving an lockdep-RCU error message if (1) the specified lockdep condition does not hold and (2) not under the protection of rcu_read_lock_sched() or friend (2.6.37 or later). | |
srcu_dereference_check() | Fetch an SRCU-protected pointer, giving an lockdep-RCU error message if (1) the specified lockdep condition does not hold and (2) not under the protection of the specified srcu_read_lock() (2.6.37 or later). | |
rcu_dereference_index_check() | Fetch an RCU-protected integral index, giving an lockdep-RCU error message if the specified lockdep condition does not hold. | |
rcu_access_pointer() | Fetch an RCU-protected value (pointer or index), but with no protection against concurrent updates. This primitive is normally used to do pointer comparisons, for example, to check for a NULL pointer. | |
rcu_dereference_raw() | Fetch an RCU-protected pointer with no lockdep-RCU checks. Use of this primitive is strongly discouraged. If you must use this primitive, add a comment stating why, just as you would with smp_mb(). |
2014 更新
引入了kfree_rcu(p, rh)。在模块卸载函数中,使用kfree_rcu后,就不需要使用rcu_barrier()了。
引入RCU_INIT_POINTER()、RCU_POINTER_INITIALIZER()。
2019更新
4.20之后,引入了RCU preempt。RCU preempt等待bh-disable, irq-disable, preempt-disable代码区域的结束。
Stallwarn
下列情况可能导致RCU CPU Stall Warnings
1 RCU read-side critical section存在死循环。
2 中断被关闭状态,然后死循环。
3 抢占被关闭,然后死循环
4 下半部被关闭,然后死循环。
5 在关闭抢占的内核中,CPU循环,不调用schedule()。
参考
[1] Paul E.McKenney. A Tour Through RCU's Requirements
https://www.kernel.org/doc/Documentation/RCU/Design/Requirements/Requirements.html
[2] RCU concepts.
https://www.kernel.org/doc/html/latest/RCU/
[3] Paul E. McKenney. Jonathan Walpole. What is RCU, Fundamentally? 2007, Linux Weekly News.
https://lwn.net/Articles/262464/
[4] Paul E. McKenney. Jonathan Walpole. What is RCU? Part 2: Usage. 2007, Linux Weekly News.
https://lwn.net/Articles/263130/
[5] Paul E. McKenney. Jonathan Walpole. RCU part 3: the RCU API. 2007, Linux Weekly News.
https://lwn.net/Articles/264090/
[6] What is RCU? -- "Read, Copy, Update"
https://www.kernel.org/doc/Documentation/RCU/whatisRCU.txt
[7] What is RCU, Really?
http://www.rdrop.com/users/paulmck/RCU/whatisRCU.html
[8] The design of preemptible read-copy-update
https://lwn.net/Articles/253651/
[9] Paul E. McKenney. Memory Ordering in Modern Microprocessors. Draft of 2007/09/19 15:15
http://www.rdrop.com/users/paulmck/scalability/paper/ordering.2007.09.19a.pdf
[10] Introduction to RCU.
http://www2.rdrop.com/users/paulmck/RCU/
[11] RCU-preempt: What happens on a context switch.
http://www.joelfernandes.org/linuxinternals/2018/05/10/5-rcu-preempt-context-switch.html
[12] The design of preemptible read-copy-update.
https://lwn.net/Articles/253651/
[13] The RCU API table. https://lwn.net/Articles/419086/
[14] The kernel lock validator. https://lwn.net/Articles/419086/
[15] The RCU API, 2010 Edition. https://lwn.net/Articles/418853/
2014:https://lwn.net/Articles/609904/
2019:https://lwn.net/Articles/777036/
[16] https://www.kernel.org/doc/Documentation/RCU/stallwarn.txt